This post was inspired by great article on Bostata.com called “Client-side instrumentation for under $1 per month. No servers necessary.“
Sounds pretty good, right?
In brief the author, Jake, describe how you can build data warehouse collecting events from your website using Snowplow event tracker on Amazon Web Services stack:
- Cloudfront to record events
- S3 to store row and processed data
- Lambda to enrich row data
- Athena to process it and provide access to the data in SQL format
The end result is data stored in S3, which is essentially just text storage and processed on fly with AWS Athena. So you pretty much own your business data, which is very in line with the philosophy of this blog.
Plus it should be cheap – no always running servers used, S3, Lambda and Athena are inexpensive, especially on comparatively small data that small & medium businesses generate.
Hence I can’t miss the opportunity to give this approach a try with help from my colleague from Magenable.
I will not repeat Jake, you need to read an original post, just stress several things that were not so obvious.
Snowplow
Snowplow is a platform to collect events data. Think about your own Google Analytics, more precisely tracking part.

We didn’t have much experience with Snowplow, so had to learn few things. Probably the most important is tracker itself, Javascript code that your call from your website page.
It can be both self-hosted and hosted by Snowplow for public. We used public one for the experiment, but setting up own isn’t that hard, you can have it with S3, so no need to have a real server.
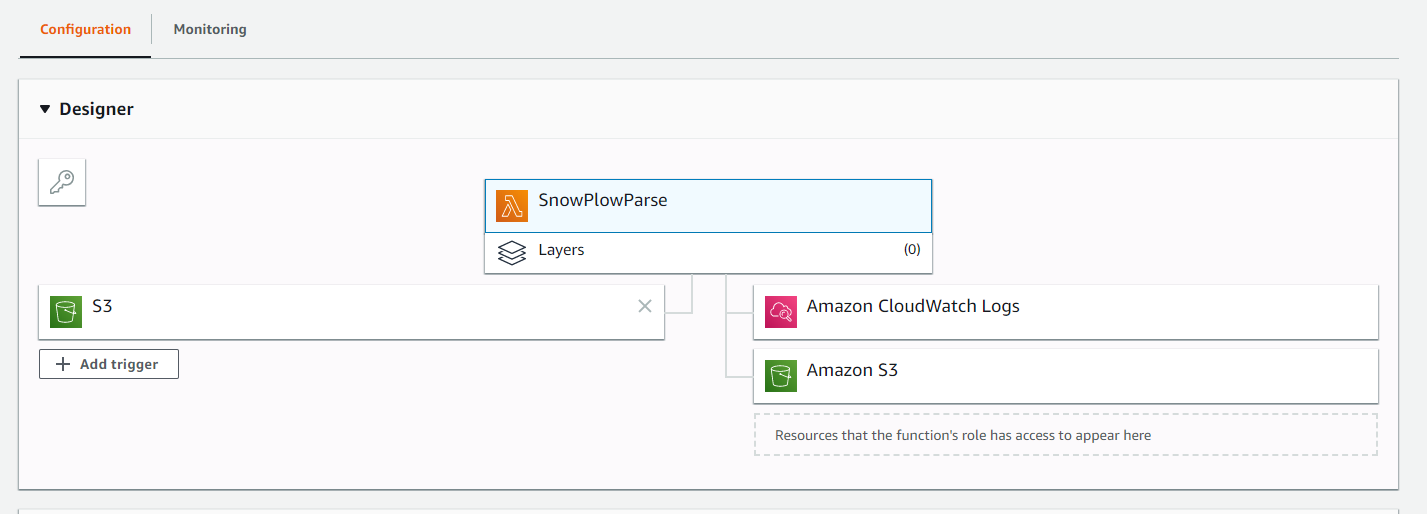
Data enrichment (Lambda)
Without enrichment you get very basic data from your tracker and you need to clean it to make it easier for further processing. Hence we need to do data enrichment. In original Snowplow architecture enrichment is done using one of 3 applications. They are open-source and can be hosted on AWS EC2. However we try to do it cheaper and use serverless Lambda function. Unfortunately the details of this process was omitted in Jake’s post. So that was the hardest part in our experiment.
Lambda supports number of programming languages including Python, which we decided to use for our simple enrichment script. It took some time, but eventually Lambda function was ready, deployed and started to work. It takes raw data from one S3 folder, processes it and puts to another S3 folder.
You may find the function on Gitgub – https://github.com/ownyourbusinessdata/snowplow-s3-enrich
It contains number of files mainly because we need to work with Maxmind Lite database of geoIP data.
Another source of enrichment is Cloudfront logs.
At the moment the function covers around 60 attributes, but we have just started.
Plugging in analytic tools
Once the data collected and Athena is configured you can get access to it in SQL form and plug almost any decent analytical tool. We’ve tried AWS own Quick Sight, Mode Analytics and R, but probably cover how it was done in another blog post.
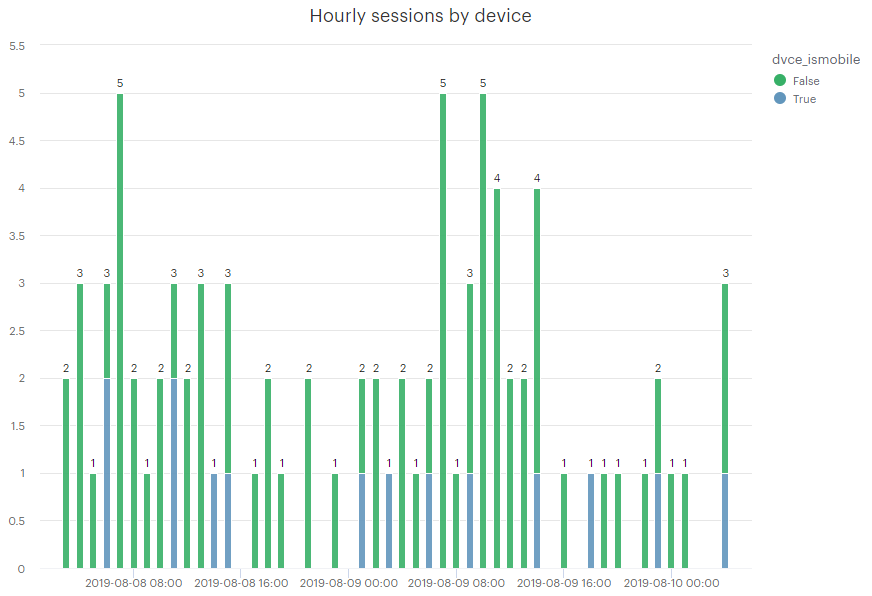
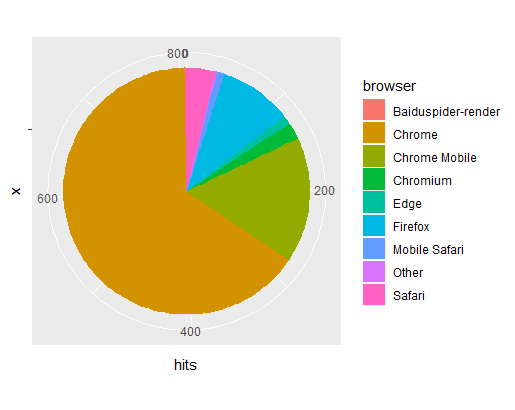
Just add there couple charts quickly produced from the data collected.
Update: Terraform script added for quick and easy deployment
We’ve added Terraform script that automates creation of AWS infrastructure, so you can deploy tracking described above quickly! Check it in our Github repository
Wouldn’t this cause an inifinite loop given that you are listening to objectCreated from s3 and using that same bucket for the processed data?
No, the raw and processed data have different prefixes and stored in different folders.